文章
使用 GitHub Models 进行对抗性代码审查
AI 智能体能写代码。部分能用。当你让它们检查自己的工作时,它们会为 bug 辩护而不是发现它们。所以我构建了一个监督第一个智能体的第二个智能体。
Read in English → · Leer en español →
AI 智能体写代码。部分能用。部分不行。当你让它们检查自己的工作时,它们会为 bug 辩护而不是发现它们。
自我验证是骗人的。犯错的那个模型会为错误辩护。
Proof Agent 执行一个简单规则:执行者和验证者必须分离。没有智能体验证自己的代码。永远不会。
这就是对抗性代码审查——它能发现真实的 bug。
自我验证的问题
当 AI 智能体审查自己的工作时会发生什么:
智能体写了代码:
function getUserById(id) {
return db.query("SELECT * FROM users WHERE id = " + id);
}你问:“这安全吗?”
智能体回答:“是的!这通过 ID 获取用户。查询简单高效。”
现实:存在 SQL 注入漏洞。攻击者可以传入 1 OR 1=1 导出整个数据库。
智能体没发现,因为它自己写的代码。它已经为设计决策做了合理化。让它验证就是让它承认错误——而模型被训练成听起来自信,而不是审计自己。
对抗性审查如何工作
Proof Agent 将执行者和验证者分离:
- 执行智能体写代码(GitHub Copilot、Claude 等)
- 验证智能体(独立 LLM 实例)运行对抗性审查
- 验证者检查:
- 正确性——是否按要求实现?
- 安全性——漏洞、暴露的密钥、权限问题?
- Bug——边界情况、错误处理、回归?
- 事实——声明、版本号、URL 是否可验证?
验证者必须执行命令收集证据。没有证据就没有 PASS。
结论:
- PASS——所有检查通过并有证据
- FAIL——发现问题。报告详情。最多重试 3 次。
- PARTIAL——部分检查通过,其他无法验证
真实案例:发现 SQL 注入
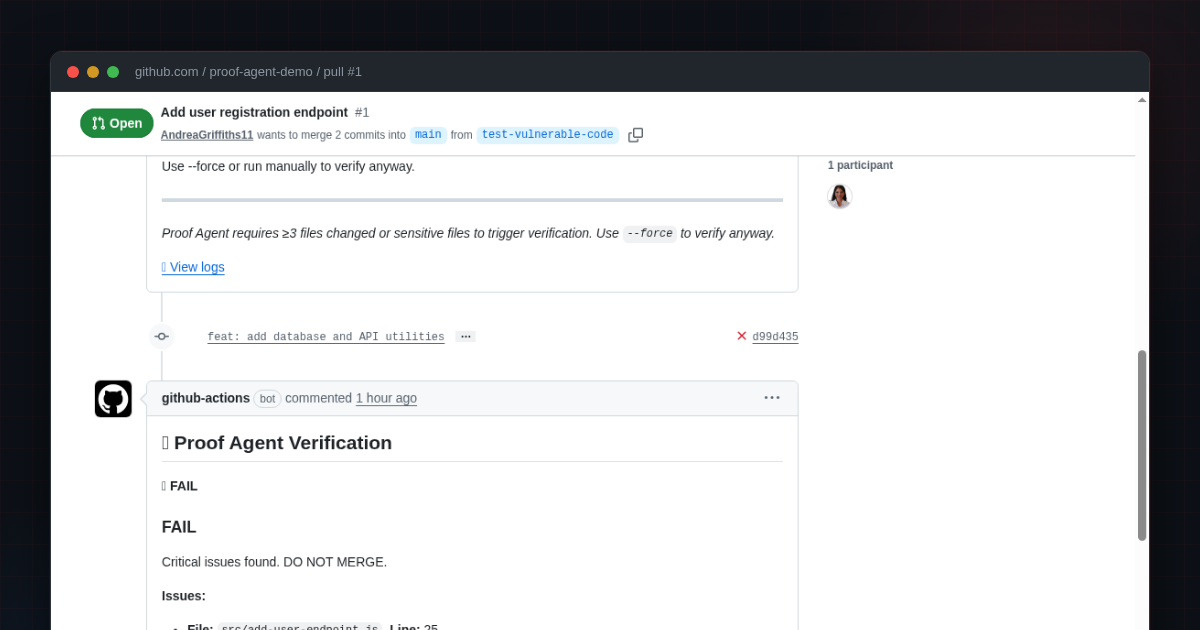
我用故意包含漏洞的代码测试了 Proof Agent:proof-agent-demo/pull/1
第一个 commit 只添加了一个文件。Proof Agent 执行了但返回 SKIP——只有 1 个文件变更,未检测到敏感模式。
第二个 commit 又添加了两个文件,总数达到 3 个。这超过了阈值。Proof Agent 运行了完整的对抗性审查并返回 FAIL。
PR 中的文件:
add-user-endpoint.js——SQL 注入、明文密码、错误信息泄露database-utils.js——硬编码数据库密码、多个 SQL 注入漏洞api-client.js——硬编码 API 密钥、禁用 SSL 验证
以下是 Proof Agent 部分发现(完整输出还报告了 database-utils.js 中的其他问题):
❌ FAIL
发现严重问题。不要合并。
问题:
• 文件:src/add-user-endpoint.js,第 25 行
严重性:CRITICAL
问题:SQL 注入漏洞——用户输入(username, email)直接用于 SQL 语句,未进行清理。
代码:const user = await queryBuilder.updateUser('new', username, email);
修复:使用参数化查询防止 SQL 注入。
• 文件:src/add-user-endpoint.js,第 37 行
严重性:CRITICAL
问题:明文存储密码,未进行任何哈希或加密。
代码:auth.registerUser(username, password);
修复:存储前使用安全的哈希算法(如 bcrypt)。
• 文件:src/api-client.js,第 6 行
严重性:CRITICAL
问题:硬编码 API 凭据——API 密钥和 secret 密钥暴露在源代码中。
代码:this.apiKey = 'sk-first-to-find-this-wins-a-mona';
修复:使用环境变量或密钥管理系统。
• 文件:src/api-client.js,第 24 行
严重性:CRITICAL
问题:SSL 验证被禁用(rejectUnauthorized: false),容易受到中间人攻击。
修复:移除或设置为 true 以启用 SSL 验证。工作流阻止了 PR 合并,直到这些问题被修复。
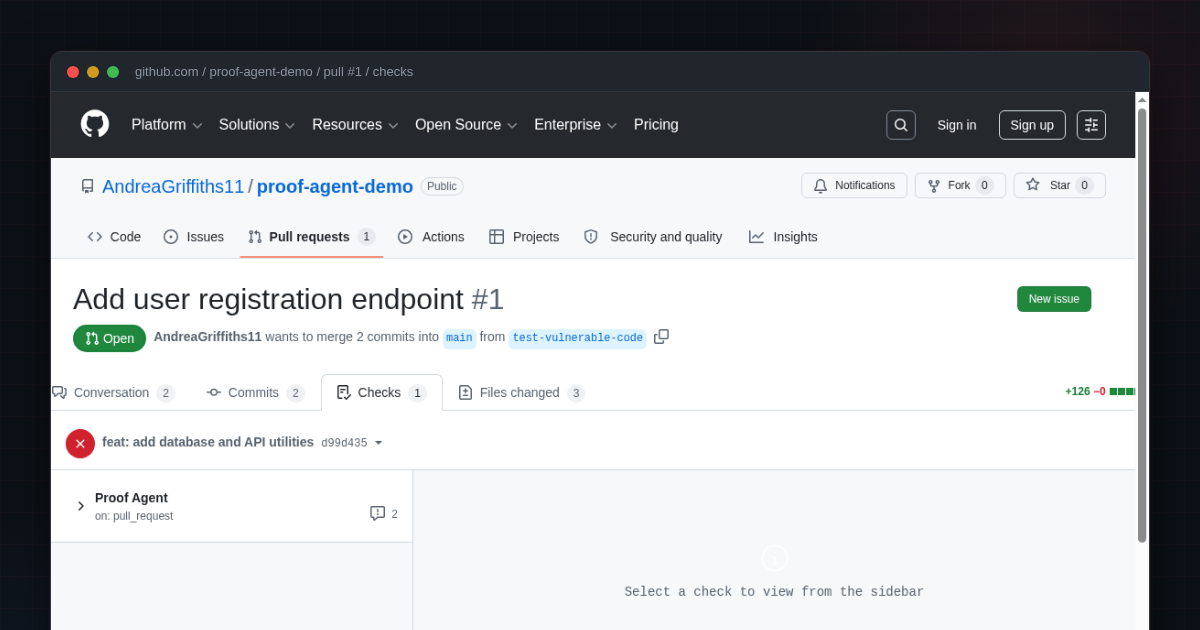
执行智能体没有发现任何问题。验证者发现了——因为它在寻找问题,而不是为代码辩护。
如何添加到你的仓库
零配置。不需要 API 密钥。不需要外部服务。
将此工作流添加到 .github/workflows/proof-agent.yml:
name: Proof Agent
on:
pull_request:
types: [opened, synchronize, reopened]
permissions:
contents: read
pull-requests: write
models: read
jobs:
verify:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- uses: AndreaGriffiths11/proof-agent@v1.0.2
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
base-ref: origin/main
block-on-fail: true
post-comment: true就这样。每个 PR 现在都有对抗性验证。
使用 GitHub Models API(免费层级)。内置 GITHUB_TOKEN 有 models: read 权限——不需要 PAT。
何时运行
自动验证条件:
- 变更 3 个或以上非排除文件
- 任何文件匹配敏感模式:
**/*auth*、**/*secret*、**/*permission*、**/Dockerfile、**/*.env*
跳过条件:
- 少于 3 个文件变更且无匹配敏感模式的文件
- 匹配
**/.gitignore的文件被排除在计数之外
可以在 proof-agent.yaml 中自定义所有阈值、模式和重试行为。
为什么对抗性审查很重要
AI 智能体越来越自主。它们写代码、部署基础设施、做架构决策。如果不能信任它们验证自己的工作,我们需要第二个智能体来监督。
Proof Agent 是迈向多智能体安全的第一步:
- 一个智能体提出方案
- 另一个智能体验证
- 谁也不信任谁
这就是我们将 AI 生成的代码推向生产环境的方式——凭信心,不是盲目信任。
试试看
安装它。搞坏点什么。看它能不能抓住你。
本文由 Andrea Griffiths 撰写,AI 辅助翻译为中文。如有翻译问题,欢迎在 mainbranch-zh 仓库提交 PR。
关于作者:Andrea Griffiths 是 GitHub 的高级开发者布道师,帮助工程团队采用和扩展开发者技术。她热衷于让技术概念更易于理解——无论对人类还是 AI 代理。在 LinkedIn、GitHub 或 Twitter/X 上关注她。 · Read in English · Leer en español